RCNN是目前最准确的图像目标检测方法之一,一直是Imagenet获奖的热门算法。RCNN从发表出来,出现了SPPNET、Fast-RCNN、Faster-RCNN等一系列改进。学习和比较其中的演进一定可以帮助我们更深刻理解这一类方法。
RCNN出世
最早的RCNN是Ross Girshick提出的一种通用的目标检测方法,将深度网络引入到目标检测任务中,使得Pascal VOC challenge的mAP一下子提高了20%多。虽然RCNN算法已经有了许多改进,但是重读RCNN论文还是可以很多收益,特别是和当时其它将CNN引入目标识别算法比较,为什么RCNN可以将精度提高这么多? 该论文有两大创造:
- 第一点是新的基于Region的目标识别算法RCNN。RCNN的算法示意图如下
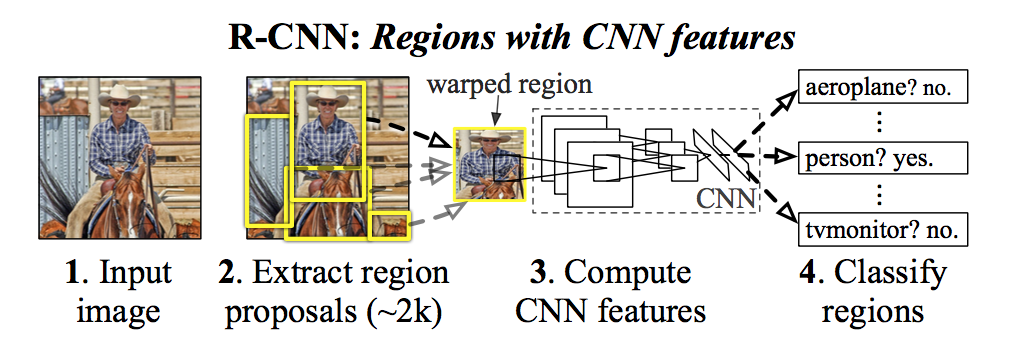 。RCNN先由Region Proposal算法(具体算法可有多种选择,比如selective search,CPMC)识别存在潜在目标的区域,再由CNN生成前面得到区域的特征,最后由目标类数目个SVM分类器识别建议区域中有无物体,或者是什么物体。为了提高目标识别的mAP,RCNN还使用了回归算法进一步提高获取目标Bounding Box的位置精度,因为mAP的计算还要检测目标和标准结果的重合程度。
。RCNN先由Region Proposal算法(具体算法可有多种选择,比如selective search,CPMC)识别存在潜在目标的区域,再由CNN生成前面得到区域的特征,最后由目标类数目个SVM分类器识别建议区域中有无物体,或者是什么物体。为了提高目标识别的mAP,RCNN还使用了回归算法进一步提高获取目标Bounding Box的位置精度,因为mAP的计算还要检测目标和标准结果的重合程度。 - 第二点论文还介绍了可以利用辅助数据集进行预训练CNN,来解决训练数据较少的问题。因为Pascal VOC的训练数据较少,而ILSVRC 2012数据集的样本就很多,先在较多的样本上进行预训练,可以防止出现过拟合的情况。也说明CNN网络具有很好的抽象能力,能够表示与具体数据集无关的语义。
亚洲的回应
RCNN发表之后的一年微软亚洲研究院的He Kaiming等就发表了SPPNET。SPPNET在CNN中添加了Spatial Pyramid Pooling Layer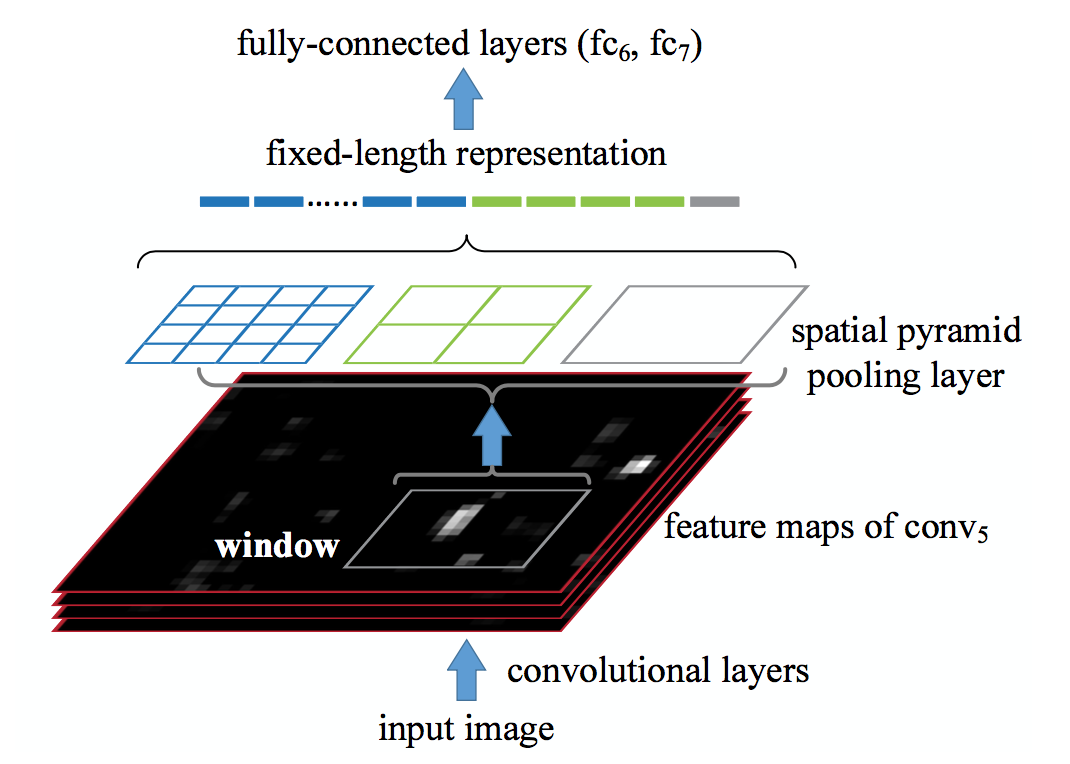 ,CNN可以不限制输入图像的尺寸(AlexNet等网络因为全连接层限制,只能处理固定长宽的图像)。由于RCNN中Region Proposal是在输入图像上生成的,有可能生成2000多个Region Proposal,RCNN计算非常耗时,即使使用GPU加速RCNN一次检测需要十几秒钟时间。其实许多Region Proposal是互相重叠的,有一些CNN计算是重复的。He Kaiming的SPPNET就可以解决这个问题,他们将RCNN的Region Proposal从CNN的输入挪到了最后一个卷积特征上,在每一个Region Proposal上使用SPPNET输出固定长度的特征,再和RCNN一样使用SVM识别是哪一类物体。这个新方法可以在1s内检测一张图片,而且保持和RCNN一样的准确性。
,CNN可以不限制输入图像的尺寸(AlexNet等网络因为全连接层限制,只能处理固定长宽的图像)。由于RCNN中Region Proposal是在输入图像上生成的,有可能生成2000多个Region Proposal,RCNN计算非常耗时,即使使用GPU加速RCNN一次检测需要十几秒钟时间。其实许多Region Proposal是互相重叠的,有一些CNN计算是重复的。He Kaiming的SPPNET就可以解决这个问题,他们将RCNN的Region Proposal从CNN的输入挪到了最后一个卷积特征上,在每一个Region Proposal上使用SPPNET输出固定长度的特征,再和RCNN一样使用SVM识别是哪一类物体。这个新方法可以在1s内检测一张图片,而且保持和RCNN一样的准确性。
Ross的回击
作为对SPPNET的回应,Ross很快发表了Fast-RCNN,提出了更快,更准的算法。该算法相对于RCNN有如下改进: *. 和SPPNET一样对整个图像只做一遍CNN计算。Fast-RCNN的做法是将输入图像上的Region Proposal区域映射到CNN的输出特征上,在输出特征上叠加了ROI Pooling Layer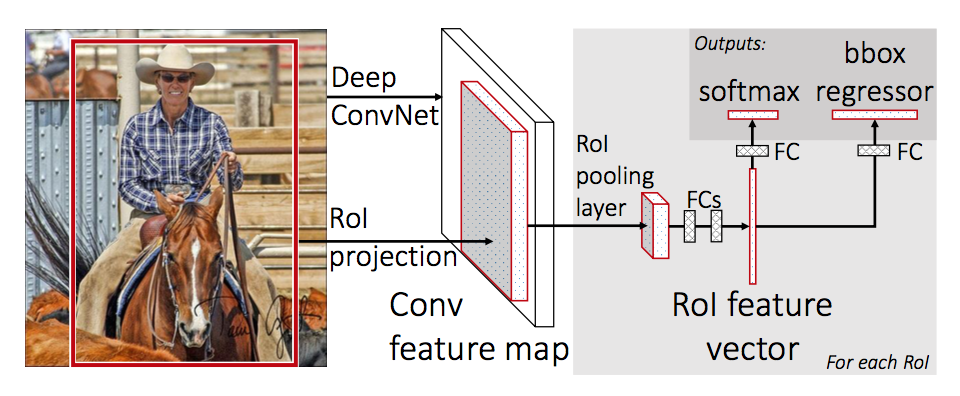 ,无论Region的大小输出长度固定的特征。ROI Pooling Layer有点像只包含一个尺度的Spatial Pyramid Pooling。 *. RCNN的类别识别和物体定位是两个分开的步骤,怎么样训练类别识别SVM和物体位置回归网络就是一个需要考虑的问题,而且需要更长的训练时间。Fast-RCNN使用一个合一的代价函数将两个网络的训练合到了一起,可以将物体识别SVM和定位回归网络一起训练到最佳状态。
,无论Region的大小输出长度固定的特征。ROI Pooling Layer有点像只包含一个尺度的Spatial Pyramid Pooling。 *. RCNN的类别识别和物体定位是两个分开的步骤,怎么样训练类别识别SVM和物体位置回归网络就是一个需要考虑的问题,而且需要更长的训练时间。Fast-RCNN使用一个合一的代价函数将两个网络的训练合到了一起,可以将物体识别SVM和定位回归网络一起训练到最佳状态。
巨牛合璧
虽然Fast-RCNN已经够好了,但是Ross和Ren Shaoqing,He Kaiming等人仍然找到了提高的地方,那就是Fast-RCNN使用的Region Proposal算法成了计算瓶颈。Faster-RCNN中不再使用传统的Region Proposal算法,而是发明了基于CNN的Region Proposal Network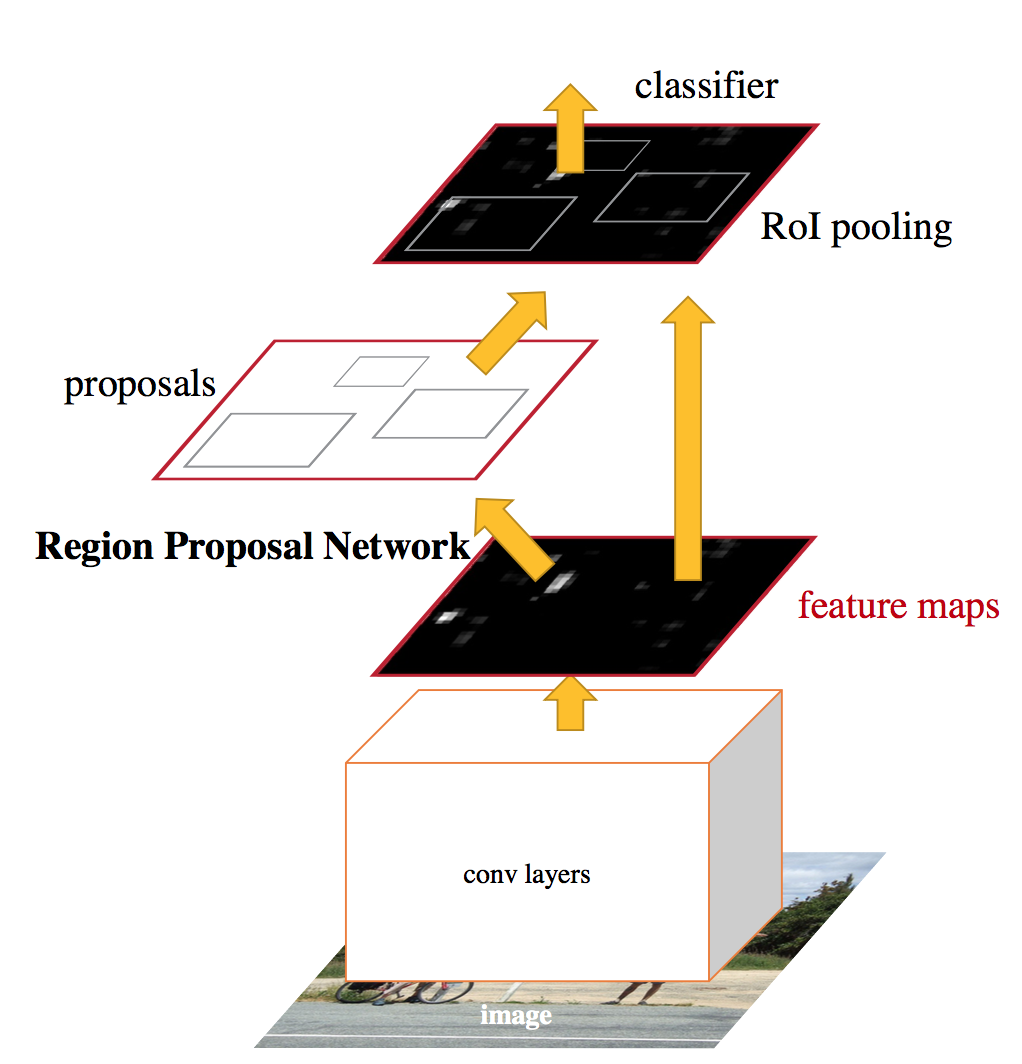 。CNN怎样生成Region Proposal呢,作者利用了一个叫Anchor的概念。CNN输出层的每一个像素处都有一个Anchor,以每个Anchor为中心又定了k个不同的矩形框Anchor Box
。CNN怎样生成Region Proposal呢,作者利用了一个叫Anchor的概念。CNN输出层的每一个像素处都有一个Anchor,以每个Anchor为中心又定了k个不同的矩形框Anchor Box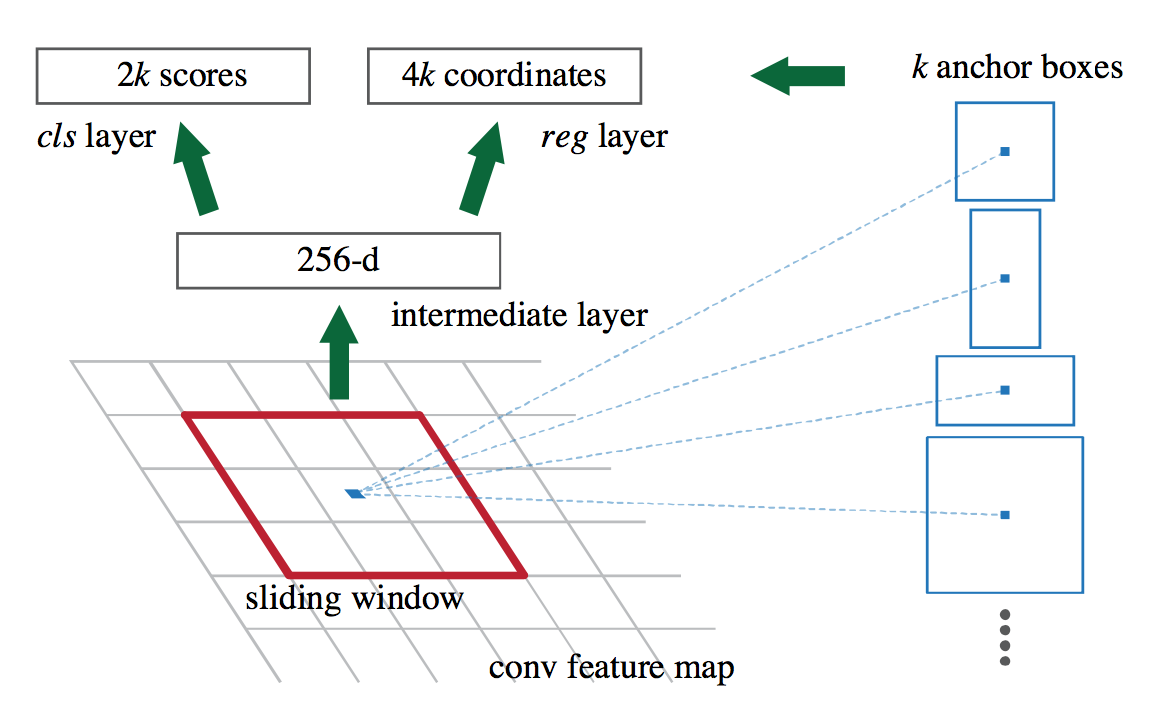 ,分别对应3种大小和3种长宽比的组合。RPN以一个Anchor为中心的n x n的CNN输出特征作为输入,对每个Anchor Box输出是否有物体的可能以及目标相对Anchor Box的偏移和大小,共(2+4)*k个输出。注意Anchor Box并不影响RPN的输入大小,RPN的输入还是一个位于CNN输出层上的n x n的滑动窗口,Anchor Box在训练过程和退到过程中做为一个Region Proposal的参考对象被使用。Faster-RCNN的物体识别网络和Fast-RCNN一样,最后就是要让RPN和Fast-RCNN共享CNN,作者采用交替训练的方式:先训练RPN,再用RPN的Region Proposal去训练物体识别网络,然后使用训练物体识别网络的CNN参数重新初始化RPN的CNN部分,固定CNN的参数,再训练RPN独有的网络部分。
,分别对应3种大小和3种长宽比的组合。RPN以一个Anchor为中心的n x n的CNN输出特征作为输入,对每个Anchor Box输出是否有物体的可能以及目标相对Anchor Box的偏移和大小,共(2+4)*k个输出。注意Anchor Box并不影响RPN的输入大小,RPN的输入还是一个位于CNN输出层上的n x n的滑动窗口,Anchor Box在训练过程和退到过程中做为一个Region Proposal的参考对象被使用。Faster-RCNN的物体识别网络和Fast-RCNN一样,最后就是要让RPN和Fast-RCNN共享CNN,作者采用交替训练的方式:先训练RPN,再用RPN的Region Proposal去训练物体识别网络,然后使用训练物体识别网络的CNN参数重新初始化RPN的CNN部分,固定CNN的参数,再训练RPN独有的网络部分。
总结
从RCNN到SPPNET、Fast-RCNN、Faster-RCNN,其中使用的改进方法也不是完全崭新的东西。但是作者的优化算法的思路,应该是最有价值,也是最值得我们学习的。