AI聊天盒子 - 使用esp-sr和Rust语言编写语音识别程序
前言
我在查找资料时,看到一个叫xiaozhi-esp32的项目。这个项目实现了一个AI盒子,允许用户自定义一个可以交互的虚拟好友。这个项目非常受欢迎,但这个AI盒子需要一个后台服务xiaozhi.me来支撑,AI盒子作为语音处理的前端设备。看来已经有人想到AI盒子的想法了,我打算实现一个不需要额外增加后台服务的AI盒子,可以直接向LLM提问。
这一篇文章是我尝试使用esp-sr实现语音识别的一个总结。本文设计的代码可以在代码仓ai-chatbox(链接在附录中),使用的硬件是XIAO ESP32S3 Sense。
本系列其他文章
编写语音识别程序
创建Rust on ESP项目并引入esp-sr
需要解决的第一个问题是如何将esp-sr添加到Rust on ESP项目中。首先创建一个Rust on ESP项目,进入Rust on ESP开发环境(如何创建Rust on ESP开发环境请参考“准备Rust on ESP开发环境”),执行命令 cargo generate esp-rs/esp-idf-template cargo , 根据提示创建一个空的Rust on ESP项目。由于esp-sr不是esp-idf中默认包含的代码库,需要我们显式地引入这个代码库。我们知道在C/C++项目中可以通过 idf.py add-dependency espressif/esp-sr 来添加扩展库,但是在Rust on ESP项目中如何做呢?通过查看esp-idf-sys编译选项,可以在 package.metadata.esp-idf-sys 配置段中添加 extra_components 配置项来引入扩展库。在Cargo.toml中添加如下配置。
[package.metadata.esp-idf-sys]
esp_idf_tools_install_dir = "global"
esp_idf_sdkconfig = "sdkconfig"
esp_idf_sdkconfig_defaults = ["sdkconfig.defaults", "sdkconfig.defaults.ble"]
extra_components = [
{ remote_component = { name = "espressif/esp-sr", version = "^2.0.0" }, bindings_header = "esp_sr_bind.h", bindings_module = "esp_sr" }
]
因为Rust需要为用到的esp-sr接口生成Rust绑定,我们还需要添加一个头文件 esp_sr_bind.h ,其中包含了可能用到的esp-sr接口头文件。Rust使用的绑定工具bindgen通过这个头文件来查找哪些C接口需要生成Rust绑定。生成的Rust接口可以在文件 target/xtensa-esp32s3-espidf/debug/build/esp-idf-sys-*/out/bindings.rs 中看到。
另外我们还需要添加partition.csv,内容如下。我们需要增加一个名为model的flash分区,为esp-sr生成的AI模型提供存储空间。
# Espressif ESP32 Partition Table
# Name, Type, SubType, Offset, Size
factory, app, factory, 0x010000, 2048K
model, data, spiffs, , 5168K
使用esp-sr接口
esp-sr库主要包含语音前端框架、唤醒词检测、语音活动检测、命令词识别、文字转语音功能五个模块。这里语音前端框架是整个语音处理流程的框架模块,支持噪声抑制、回声抑制、语音活动检测、唤醒词检测等算法。命令词识别模块的输入数据也需要经过语音前端框架的处理。唤醒词检测支持用较低的资源开销检测特定的唤醒词,唤醒词是esp-sr预包含的,如许定制唤醒词需要向乐鑫公司提需求。语音活动检测是检测用户有无语音输入。命令词识别比唤醒词检测更加灵活,支持用户自定义命令词,可以识别多达200个命令,但消耗的资源要多很多,这两种功能一般会配合使用。文字转语音就是将文字转成语音的功能。目前ai-chatbox只用到了前四个模块,文字转语音功能以后再尝试。
与语音识别相关的代码主要包含在 main.rs 中。这个文件会初始化硬件和创建AFE等资源对象,然后创建两个任务。第一个Feed任务持续地从麦克风读取数据,并输入到AFE流水线中;另一个Fetch任务从AFE流水线获取经过算法处理的数据和检测结果,进行下一步的处理。
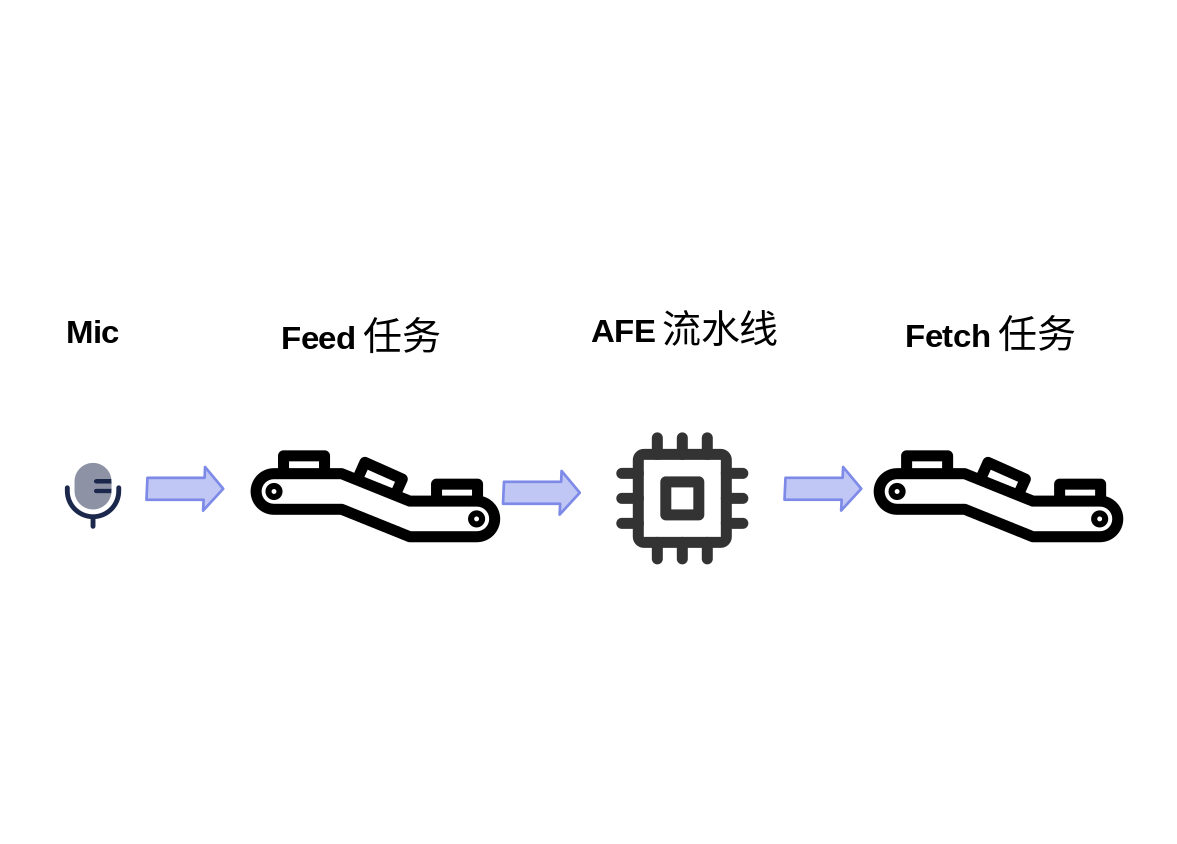
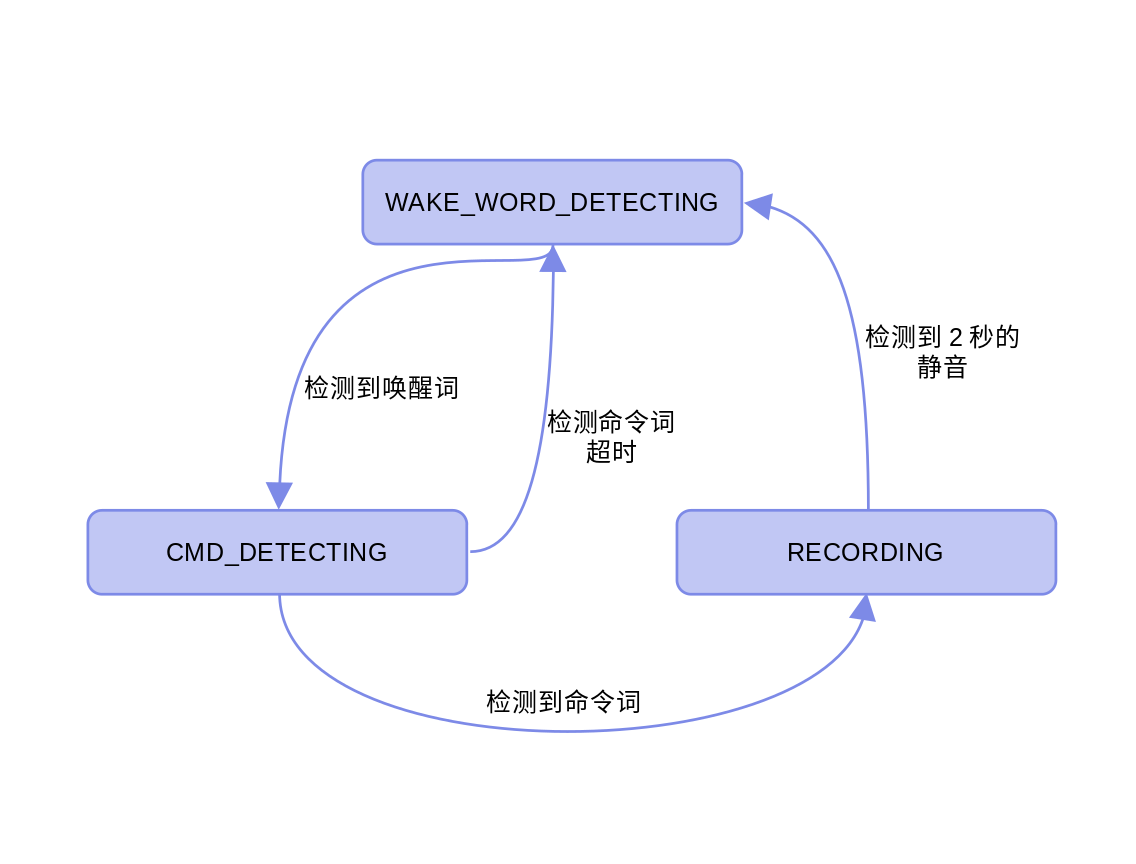
Fetch任务还维护了一个状态机,不同的事件会触发Fetch任务在几个状态之间切换。
下面我们看代码中如何使用esp-sr接口。首先我们需要创建AFE相关的对象,代码在 main 函数中。这段代码先设置AFE的配置参数,指定模型所在的分区、模型类型和运行模式等,然后通过调用 esp_afe_handle_from_config 和 create_from_config 创建了AFE方法对象和AFE数据对象。至于为什么esp-sr把AFE拆成了两个对象,我猜是因为方便把接口和实现隔离开来,隐藏实现细节。这里的 call_c_method 是个Rust宏,用于方便地在Rust中使用C函数指针,等于C++中的 afe_handle->create_from_config(afe_config) 。
let part_name = CString::new("model").unwrap();
let models = unsafe { esp_srmodel_init(part_name.as_ptr()) };
let input_format = CString::new("M").unwrap();
let afe_config = unsafe {
afe_config_init(
input_format.as_ptr(),
models,
esp_sr::afe_type_t_AFE_TYPE_SR,
esp_sr::afe_mode_t_AFE_MODE_LOW_COST,
)
};
// Print the AFE configuration
print_afe_config(afe_config);
let afe_handle = unsafe { esp_afe_handle_from_config(afe_config) };
let afe_data = call_c_method!(afe_handle, create_from_config, afe_config)?;
unsafe { afe_config_free(afe_config) };
下一步创建命令词识别相关的对象。和AFE类似命令词识别也需要两个对象,一个接口对象和一个数据对象。创建好命令词识别相关的对象后我使用了 esp_nm_commands_clear/add/update 接口动态注册了一个命令词“wo you wen ti”。
let prefix_str = Vec::from(esp_sr::ESP_MN_PREFIX);
let chinese_str = Vec::from(esp_sr::ESP_MN_CHINESE);
let mn_name = unsafe {
esp_srmodel_filter(
models,
prefix_str.as_ptr() as *const i8,
chinese_str.as_ptr() as *const i8,
)
};
let multinet = unsafe { esp_mn_handle_from_name(mn_name) };
let model_data = call_c_method!(multinet, create, mn_name, 6000)?;
unsafe {
esp_mn_commands_clear();
esp_mn_commands_add(1, Vec::from(b"wo you wen ti\0").as_ptr() as *const i8);
esp_mn_commands_update();
}
创建好了AFE和命令词识别相关的对象,下面我们创建两个FreeRTOS任务分别从麦克风获取数据输入到AFE流水线中和从AFE流水线抓取处理过的数据和结果。我们分别看一下这两个任务的代码。先看Feed任务的代码。代码在函数 inner_feed_proc 中。我先初始化了麦克风硬件,并分配语音数据缓存,然后在loop中不断从麦克风读取数据,然后调用AFE函数对象的 feed 方法,将数据输入AFE流水线中。
fn inner_feed_proc(feed_arg: &Box<FeedTaskArg>) -> anyhow::Result<()> {
let peripherals = Peripherals::take()?;
let mut mic = init_mic(
peripherals.i2s0,
peripherals.pins.gpio42,
peripherals.pins.gpio41,
)?;
let chunk_size = call_c_method!(feed_arg.afe_handle, get_feed_chunksize, feed_arg.afe_data)?;
let channel_num = call_c_method!(feed_arg.afe_handle, get_feed_channel_num, feed_arg.afe_data)?;
log::info!("[INFO] chunk_size {}, channel_num {}", chunk_size, channel_num);
let mut chunk = vec![0u8; 2 * chunk_size as usize * channel_num as usize];
loop {
mic.read(chunk.as_mut_slice(), 100)?;
let _ = call_c_method!(feed_arg.afe_handle, feed, feed_arg.afe_data, chunk.as_ptr() as *const i16)?;
}
Ok(())
}
接下来再看Fetch任务中调用esp-sr接口的地方。代码主要位于 inner_fetch_proc 函数中。为了突出调用esp-sr的地方,我删除了其中记录Wav文件相关的代码。主要部分也是一个loop循环过程,每次循环都会调用AFE流水线的 fetch 方法,这个方法会返回流水线处理过的数据和结果,然后执行一个匹配当前状态的match语句。
fn inner_fetch_proc(arg: &Box<FetchTaskArg>) -> anyhow::Result<()> {
...
loop {
// Always fetch data from AFE
let res = call_c_method!(afe_handle, fetch, afe_data)?;
if res.is_null() || unsafe { (*res).ret_value } == esp_sr::ESP_FAIL {
log::error!("Fetch error!");
break;
}
// Handle the data based on current state
match state {
State::WAKE_WORD_DETECTING => {
if unsafe { (*res).wakeup_state } == esp_sr::wakenet_state_t_WAKENET_DETECTED {
let next_state = State::CMD_DETECTING;
log::info!("Wake word detected. State transition: {:?} -> {:?}", state, next_state);
call_c_method!(afe_handle, disable_wakenet, afe_data)?;
call_c_method!(multinet, clean, model_data)?;
state = next_state;
}
},
State::CMD_DETECTING => {
let mn_state = call_c_method!(multinet, detect, model_data, (*res).data)?;
if mn_state == esp_sr::esp_mn_state_t_ESP_MN_STATE_DETECTED {
...
let next_state = State::RECORDING;
log::info!("Command detected (ID: {}). State transition: {:?} -> {:?}",
command_id_str, state, next_state);
...
state = next_state;
} else if mn_state == esp_sr::esp_mn_state_t_ESP_MN_STATE_TIMEOUT {
let next_state = State::WAKE_WORD_DETECTING;
log::info!("Command detection timeout. State transition: {:?} -> {:?}", state, next_state);
call_c_method!(afe_handle, enable_wakenet, afe_data)?;
state = next_state;
}
},
State::RECORDING => {
...
if vad_state == sys::esp_sr::vad_state_t_VAD_SILENCE {
silence_frames += 1;
if silence_frames >= frames_per_second { // More than 1 second of silence
let next_state = State::WAKE_WORD_DETECTING;
log::info!("Detected {} frames of silence. State transition: {:?} -> {:?}",
silence_frames, state, next_state);
...
// Return to wake word detection
call_c_method!(afe_handle, enable_wakenet, afe_data)?;
state = next_state;
}
} else {
// Reset silence counter when we detect speech
if silence_frames > 0 {
log::debug!("Speech detected after {} silent frames, resetting silence counter", silence_frames);
}
silence_frames = 0;
}
}
}
}
Ok(())
}
先看 WAKE_WORD_DETECTING 状态的处理,唤醒词检测的结果保存在 wakeup_state 字段中。如果字段等于 WAKENET_DETECTED ,就说明用户说出了唤醒词“Hi,lexin”。如果状态机是 CMD_DETECTING 状态,代码会调用命令词识别接口对象的 detect 方法。命令词识别算法并不在AFE流水线中,但是需要输入AFE流水线处理过的数据。 detect 方法会返回识别的结果,通过检查返回值判断有无识别到命令词。再如果状态机是 RECORDING 状态,代码会用到声音活动检测算法。这个算法包含在AFE流水线中,所以只需要检查 fetch 方法返回结果的 (*res).vad_state 字段就可以了。如果字段等于 VAD_SILENCE ,就表明用户没有说话。当前静音达到一定的时间,状态机会返回 WAKE_WORD_DETECTING 状态。
编译和上传固件
项目使用esp-sr时比普通的Rust on ESP项目多了一个刷写模型的步骤。首先接上ESP32S3进入 Rust on ESP环境 。在运行完 cargo espflash flash -p /dev/ttyACM0 --flash-size 8mb 命令后我们还要刷写esp-sr生成的模型。在 esp-idf环境下 运行命令 esptool.py --chip esp32s3 -p /dev/ttyACM0 -b 460800 --before=default_reset --after=hard_reset write_flash --flash_mode dio --flash_freq 80m --flash_size 8MB 0x210000 ./target/xtensa-esp32s3-espidf/debug/build/esp-idf-sys-ac*/out/build/srmodels/srmodels.bin 就可以将模型写入”model”分区中。
总结
本文介绍了如何使用esp-sr来完成唤醒词检测、命令识别、语音活动检测等任务,以及如何在Rust on ESP项目中使用esp-sr。在完成这个项目过程中esp-skainet给了我很多启发,关于如何使用麦克风我还参考了esp-idf中的i2s_recorder例子。本系列的后续文章中我会继续探索如何在Rust on ESP项目中使用LLM API,欢迎大家关注和转发,也欢迎大家和我交流。
链接
- ai-chatbox - https://github.com/paul356/ai-chatbox
- esp-skainet - https://github.com/espressif/esp-skainet
- i2s_recorder - https://github.com/espressif/esp-idf/tree/master/examples/peripherals/i2s/i2s_recorder