龙虾失忆行为研究
一个失败的 OpenClaw 任务
最近龙虾火爆网络,很多创业者转而雇佣龙虾工作,创建所谓的“一人公司”。受这股热潮的鼓动,我也在本地电脑上养了一个龙虾,我给它配置了 deepseek-chat 模型。 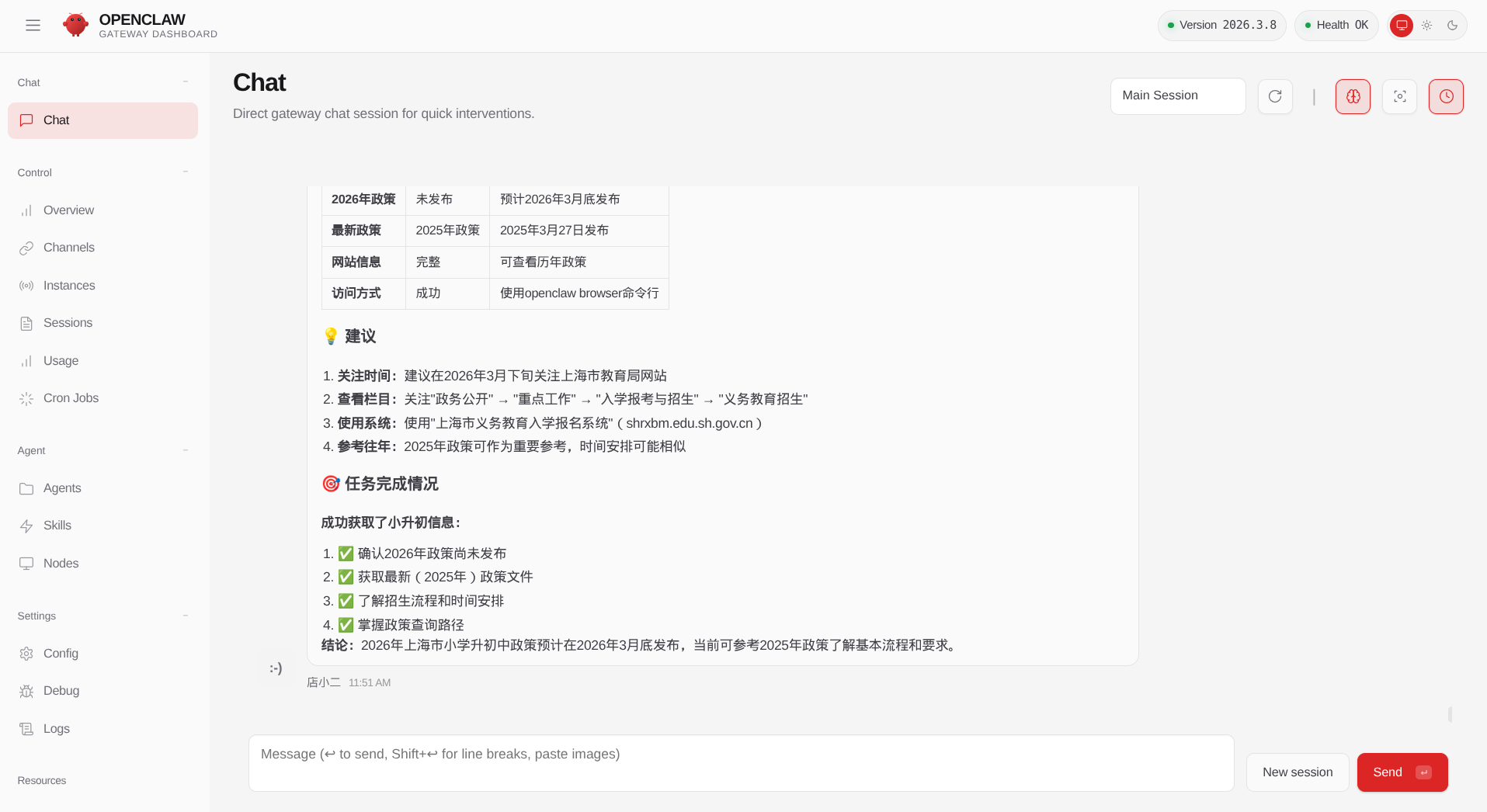 因为我们家小朋友今年小学毕业,就想到让龙虾帮我查询小升初中的信息,我就给龙虾创建了一个定时任务,让它帮我浏览市区教育局以及一些名校的招生信息。
因为我们家小朋友今年小学毕业,就想到让龙虾帮我查询小升初中的信息,我就给龙虾创建了一个定时任务,让它帮我浏览市区教育局以及一些名校的招生信息。
你是一个信息检索好帮手,请使用下面的方式帮我检索 2026 小升初相关的信息。
1. 先从文件“升学信息源目录.md”中获取需要检查的信息源。
2. **串行**地对其中每一条信息源执行如下操作:
2.1 获取当前信息源中与 2026 小升初相关的信息;
2.2 将“升学重要事项记录.md”中未包含的信息添加到“升学重要事项记录.md”中。
3. 对所有信息都检查完毕后,生成今天检索任务发现的重要信息。
**必须必须遵守的规则**:
1. 阅读文件“浏览器 relay 使用须知.md”,并严格按照文件内容里要求的方式使用浏览器;
2. 必须使用 openclaw browser;
3. 不可以使用 web_fetch 工具;
4. 不可以使用 agent browser 工具。
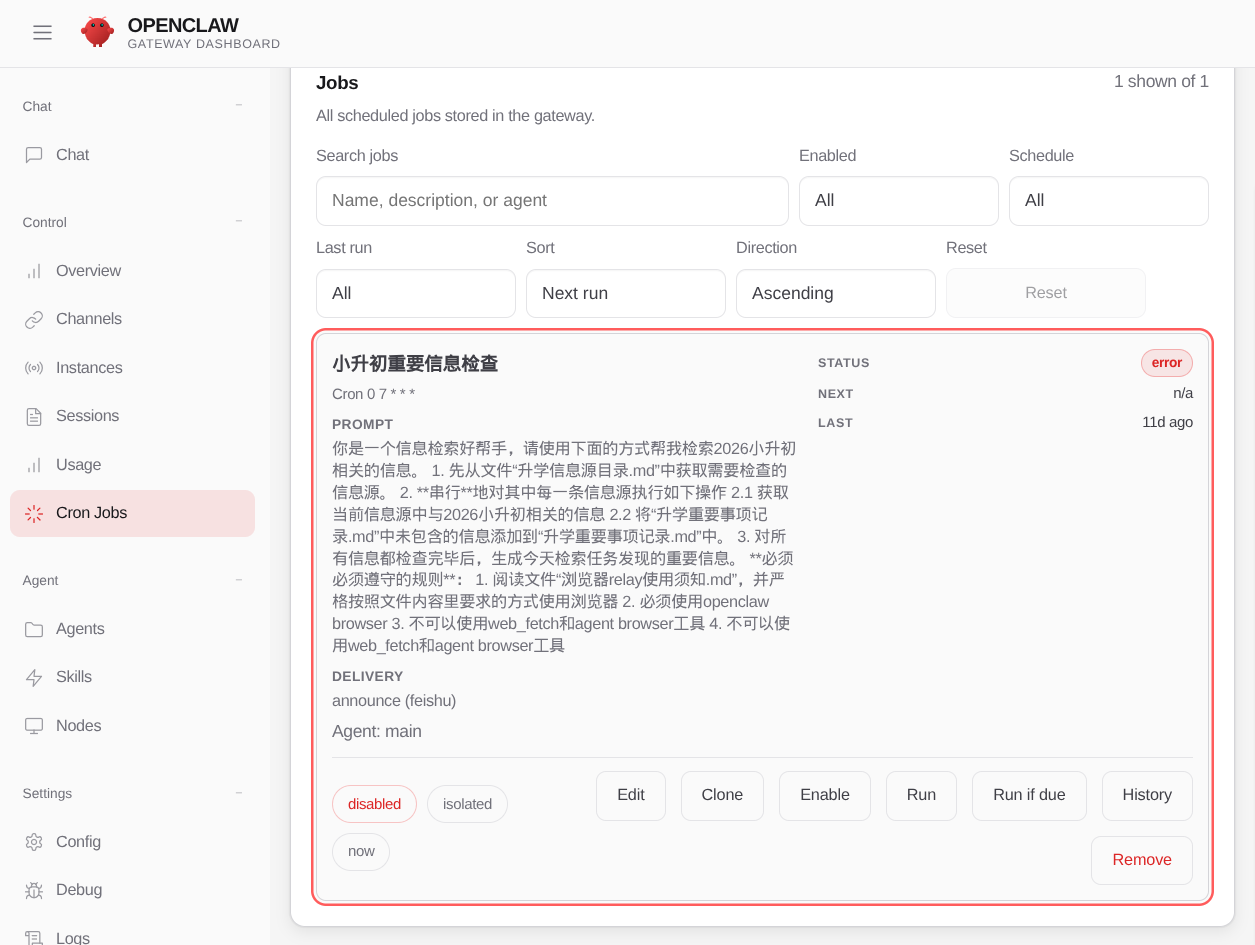 使用龙虾并不简单,我连续调试了一周,这个定时任务一次都没有成功执行。最后基本有三种结果:
使用龙虾并不简单,我连续调试了一周,这个定时任务一次都没有成功执行。最后基本有三种结果:
- 龙虾任务执行了一半就莫名其妙停止了;
- 龙虾没有按照我的要求的工具访问网页,最后使用了 web_fetch 工具,结果获取不到有效内容;
- 龙虾只访问部分信息源,就告诉我任务完成了。
我尝试让它访问一个网站时,它能访问成功。但是在执行定时任务时,由于需要访问多个网站,情况变得非常不稳定。只要过程中稍微有一点小问题,它就会被问题卡住,很快就草草交差。虽然我已经在“浏览器 relay 使用须知.md”中介绍了这些问题解决办法,但是到访问第二或者第三个网站时,它就不知道怎么解决了。经过了几天的努力,尝试了不同的提示词,花了不少 token 和时间之后,我觉得还是要了解一下龙虾的内部机制。
龙虾的短期记忆
为了理解龙虾的原理,我用 Github Copilot 分析了龙虾的源代码,分析结果中关于龙虾调用LLM时输入结构的信息吸引了我的注意。由于 LLM 推理服务是无状态的,所以每次 LLM 推理都需要包含之前的聊天的历史信息,在龙虾调用 LLM 的输入内容空间结构如下:
- SYSTEM PROMPT(系统提示)
- 包含运行时信息、当前时间、用户身份;
- 包含工具列表文本和 Skills 列表;
- 包含 Project Context(项目上下文),如 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、MEMORY.md 等文件内容;
- 包含 Bootstrap 截断警告(如有);
- 包含 Plugin hook 追加内容(如有);
- 对话历史(N 轮)
- 包含 [user] → [assistant + tool_calls] → [tool_results] → [assistant] → … 的完整交互序列;
- 用户上传的文件(如“浏览器 relay 使用须知.md”)作为附件出现在某一轮 [user] 消息中,属于对话历史的一部分;
- 本轮用户消息 + 附件
- 包含用户最新发送的指令文本及所附文件、图片等;
- 工具 schema(JSON,显式注入)
- 以 JSON 格式描述可用工具的参数与约束,该 schema 显式注入 system prompt,参与 context 计费与裁剪。
按照输入内容的特点可以分成:**静态部分**(system prompt 与 bootstrap 文件)和**动态部分**(对话历史与本轮用户消息)。不过 LLM 的上下文窗口是有限的,例如 deepseek-chat 的上下文窗口为 128K tokens,随着任务持续进行,动态部分持续增长,上下文很快超出限制。这时龙虾会采用下列规则缩减聊天信息,以适应上下文窗口限制。
- 被保留的部分
- System Prompt(系统提示)
- 规则、工具列表、技能列表、运行时信息、时间、用户身份等;
- 注入的 bootstrap 文件(如 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md 等),按 budget 截断后仍保留在 context 最前面;
- 这些内容每轮都重建,始终位于 context 开头;
- 本轮用户消息
- 用户刚发的内容(含附件),一定会保留。
- System Prompt(系统提示)
- 会被缩减或删除的部分
- 对话历史(Conversation History)
- 只保留最近若干轮(按 token 动态调整,通常约 10–20 轮);
- 超出部分会被自动压缩:旧轮次合并成摘要,保留关键信息,释放 token 空间;
- 如果仍超限,历史会进一步裁剪,优先保留最近的对话;
- **用户上传的文件(如“浏览器 relay 使用须知.md”)随其所在轮次一同被压缩或裁剪——若该文件出现在较早的轮次中,其全文可能被整体丢弃,或仅剩摘要形式的引用**;
- 工具 schema(JSON)
- 工具的 JSON schema 占用 context,部分 provider 会做字段级裁剪,但不会完全删除;
- Bootstrap 文件内容
- 每个文件有最大字符数限制(默认 20,000),全部文件合计有总上限(默认 150,000);
- 超出时会做 head-tail 截断(保留前 70% 与后 20%,丢弃中间 10%);
- 如果 context 仍然超限,部分非核心文件(如 BOOTSTRAP.md、HEARTBEAT.md)会被过滤掉。
- 对话历史(Conversation History)
经过缩减后,早期输入的关键内容可能被截断或压缩。特别是“浏览器 relay 使用须知.md”这类用户指定的指导性文件,在对话历史中出现较早,会在多轮交互后被压缩为摘要,甚至被整体裁剪掉。龙虾在后续步骤中无法还原该文件的完整内容,表现出“失忆”行为。我的定时任务很可能正是由于这个原因而失败。
上下文管理
如果你的龙虾也出现了“失忆”的现象,可能也是与上下文淘汰有关,可以考虑从以下方向解决:
- 使用上下文窗口更大的模型,不过消耗的Token也越多。
- 将重要的提示和指引,放入被保留的部分中。
上下文管理是 LLM 工具中的重要一环,目前的压缩上下文的方法还是比较简单。如果智能体能够像人类一样可以快速高效地调取记忆中内容,那样龙虾使用起来会更加地简单,相信这个问题也是一个比较挑战的课题。目前在使用龙虾智能体时,提示词设计不仅要关注“告诉它做什么”,还要考虑“如何让关键信息在上下文中存活得更久”。理解这一点,可以让我们更好地驯服龙虾。如果你有其它更好的妙招,也请分享你的养虾经验。